Generating EVM vanity addresses efficently with 'profanity2'
Cutting Gas Costs with Smart Ethereum Address Choices
Gas costs are a critical factor in any blockchain project. Every transaction, comes with an inherent price tag. While there are numerous ways to optimize these costs, one method that often flies under the radar is selecting Ethereum addresses with specific characteristics to reduce gas consumption.
At first glance, it might seem that the address you use in a transaction wouldn’t have any impact on gas fees. However, this isn’t true. Ethereum transactions often require passing addresses as part of the transaction data. When these addresses are encoded into the transaction data, the cost of encoding a zero byte is significantly less than that of encoding a non-zero byte.
Ethereum Word Composition and Storage
In the EVM, data is stored and processed in chunks of 32 byte words. Every piece of data, including addresses, must be encoded into this format before being stored or processed.When interacting with the EVM, storing or manipulating these words can be costly, especially when they contain non-zero bytes. For example:
Transaction Data: When sending a transaction that includes data (e.g., a function call with parameters), the data is encoded into bytes. Each byte in this data is charged based on whether it is zero or non-zero.
- Zero bytes cost 4 gas each.
- Non-zero bytes cost 68 gas each.
Consider the following two addresses:
- Address A: 0xdecafbad00000000000000000000000000000000
- Address B: 0x1234567890abcdef1234567890abcdef12345678
EVM words default to zero, so avoiding non-zero bytes reduces gas costs. The hamming weight, which measures the number of non-zero bits in data can be used to measure how many extra stores can be saved. Address A has a lower Hamming weight because it contains more zero bytes, as a result, using Address A in a transaction incurs lower gas fees compared to Address B.
Browser solutions
Websites like vanity-eth.tk expose the concept easily over the browser but have the disadvantage that trying to run brute-force inside the browser is crazy inefficent, and we’re trusting that they don’t send a response to their server. The latter can be mitigated by disconnecting from the internet temporarily and flushing the browser cache afterwards. Even if we assume the website is safe and doesn’t send our newly generated private key across the network, we can’t be so sure than they’d never be compromised in the future.
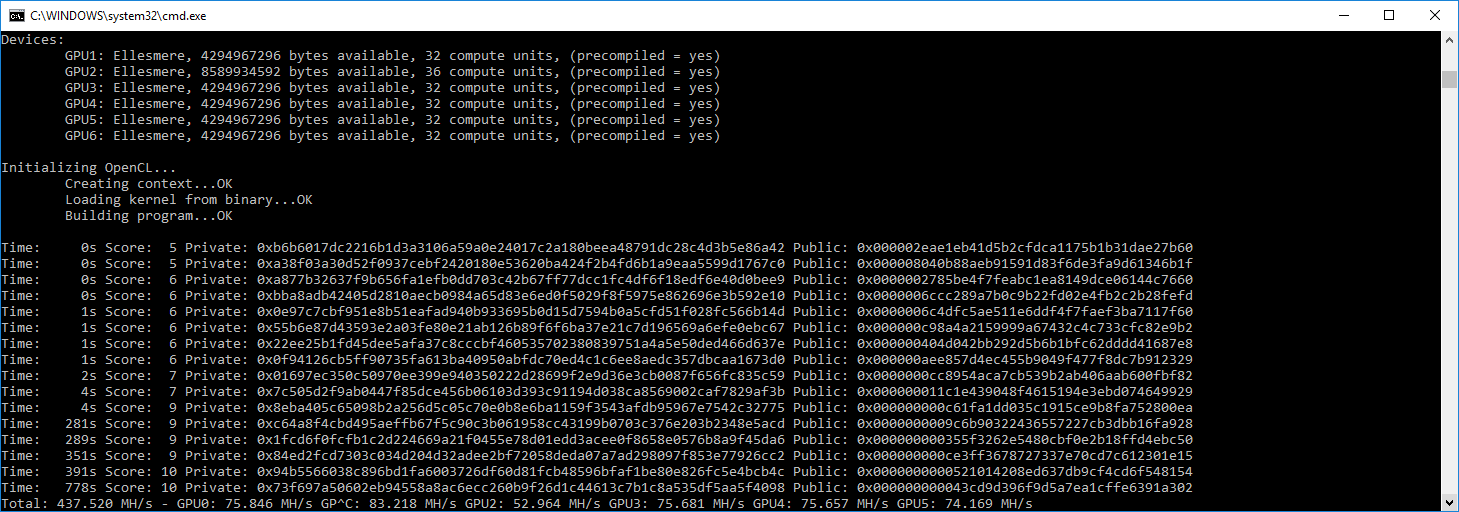
One winter I spent 3 continuous days trying to generate an 8 leading zero on an NVIDIA GTX TITAN using vanity-eth.tk which was a very electricity expensive operation. Nowadays I can generate hundreds in less than 5 minutes on my M1.
Generating leading zero addresses with Profanity2
Profanity2 is one of the fastest open sourced Ethereum vanity address generators which can find specific patterns or sequences, such as leading zeros or custom prefixes and suffixes. It works by leveraging brute-force techniques to find private keys that, when hashed using keccak-256, produce an address that matches the desired pattern.
Profanity2 requires a user provided public key which will change hex bytes and generate a new private key from them, profanity2 then computes a new Ethereum address from this manipulated public key, checking it against some specified criteria. Once a match is found, a private key which is offset from the original private key is produced. We’ll need both our original public/private key, and our generated private key
This demonstration can be easily replicated by reading through 1inch/profanity2’s readme. For those who can’t decypher the readme, my tutorial might be more digestible.
- Grab any old private key you have laying around or generate a new wallet using metamask and get it’s private key. We’ll use openssl to derive a public key from that. Remove any prefixing ‘0x’ from the private key.
openssl ec -inform DER -text -noout -in <(cat <(echo -n "302e0201010420") <(echo -n "PRIVATE_KEY_GOES_HERE") <(echo -n "a00706052b8104000a") | xxd -r -p) 2>/dev/null | tail -6 | head -5 | sed 's/[ :]//g' | tr -d '\n' && echo - That will return a 130 byte hexadecimal public key, ensuring that the prefixing ‘04’ is removed, we should be left with 128 bytes.
- Clone the 1inch/profanity2 to your machine.
git clone https://github.com/1inch/profanity2.git - Running the command which will find –leading 0’s. The -z flag is the seeding public key for the bruteforcing.
./profanity2.x64 --leading 0 -z DERIVED_PUBLIC_KEY_GOES_HERE
 Profanity generating 10 leading zeros in just over 2 hours. Notice how the private key ending is mutated.
Profanity generating 10 leading zeros in just over 2 hours. Notice how the private key ending is mutated.
- Once you’re happy with an address that’s been generated you can stop the search and run the command, removing the prefixing ‘0x’ from the newly generated PRIVATE_KEY_2.
(echo 'ibase=16;obase=10' && (echo '(PRIVATE_KEY_1 + PRIVATE_KEY_2) % FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F' | tr '[:lower:]' '[:upper:]')) | bc
What happened to Profanity1?
In September 2022, the original Profanity’s vanity addresses fell victim to an attack. Exploiting a flaw in the tool’s key generation process, attackers drained $3.3 million worth of tokens from users’ wallets.
Profanity used a pseudorandom number generator seeded with an unsigned integer, limiting the possible seed values to approximately 4.3 billion. Although this number might seem large, it was not enough to prevent brute force attacks. Estimates suggested that a setup of 1,000 GPUs could potentially crack the private keys of every 7-character vanity address generated by Profanity within 50 days. While costly, the potential rewards were significant.
In early 2022, 1inch researchers discovered and reported this vulnerability in Profanity. However, the issue gained widespread attention only after attackers exploited it, stealing $3.3 million in tokens and putting additional addresses at risk.
Read the full article released on 1inch’s blog.
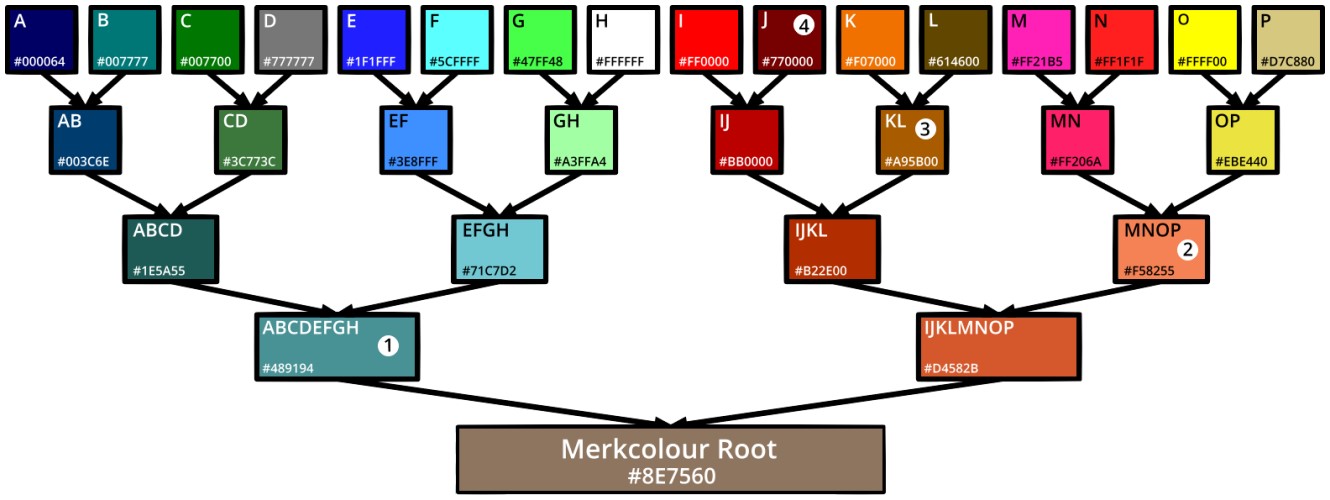
 A balanced Merkel tree with an even number of leaf nodes.
A balanced Merkel tree with an even number of leaf nodes.
 A unbalanced Merkel tree with an odd number of leaf nodes.
A unbalanced Merkel tree with an odd number of leaf nodes.
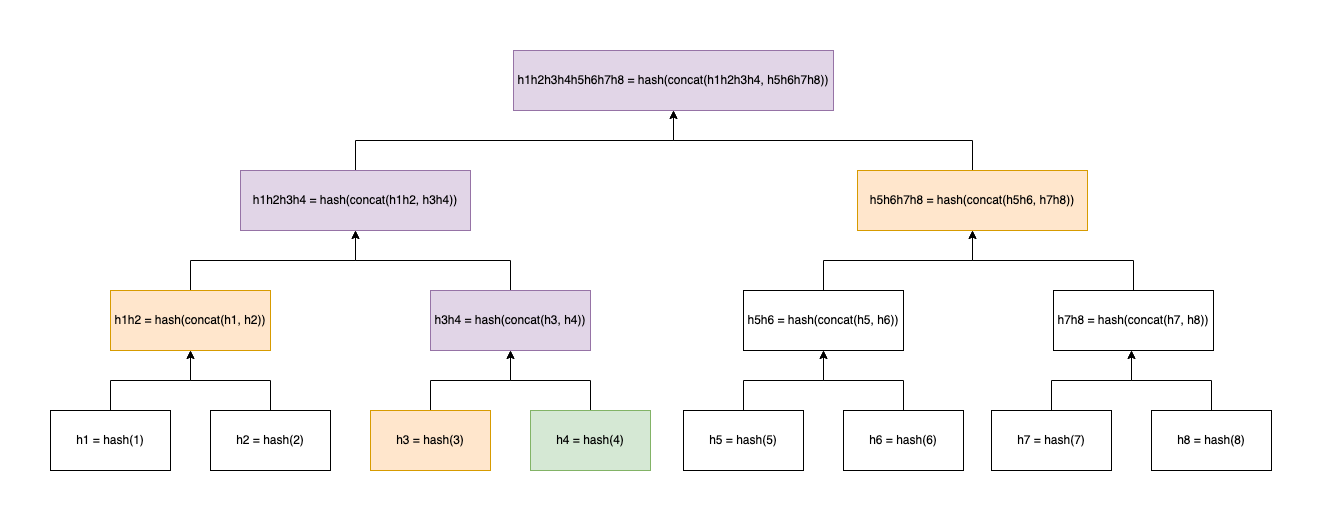 Logarithmic searching reduces the computational spend.
Logarithmic searching reduces the computational spend.